Ogg 封装 Opus 音频流
Opus 编码后的音频流不方便存储和传输,Ogg 作为一种容器格式,提供了封装 Opus 音频流的方法。封装之后音频流方便存储和传输,并且提供了一些关键特性,包括元数据,快速而精准的定点播放,封装只需要很少额外数据开销,而且方便与其它的数据流(例如视频)复合。
Ogg 封装 Opus 流的包结构
Ogg 流是由一个一个 Ogg 页(Ogg Page)组成的,每个 Ogg 页封装了来自一个或者多个“数据包”的数据。“数据包”如果太大,有可能会分散到多个 Ogg 页中。“数据包”如果比较小,一个 Ogg 页也有可能包含多个数据包。“数据包”不一定是指音频数据,也有可能是元数据等等。
一个 Ogg 封装的 Opus 音频流的格式如下图所示:
1 | Page 0 Pages 1 ... n Pages (n+1) ... |
在这个流中,有两个数据包是必须的。第一个包是 ID 头(ID Header),这个包不是 Opus 音频包,它所携带的信息表明了这个二进制流是 Opus 音频。这个 ID 头独占第一个 Ogg 页,这一页不会包含其它数据,而且 ID 头的大小也不会超过一个 Ogg 页。第一页的 Ogg 头类型标志中的 bos 标志将会被置为 1,表示逻辑流的开始。
逻辑流中的第二个必须的包叫做注解头(Comment Header),其中包含了用户创建流时提供的元信息,例如标题、发行时间、艺术家名字等等。注解头从逻辑流的第二个 Ogg 页开始,有可能太大会占据多个页,并且它结尾的那个 Ogg 页不能包含别的包的数据。
后续的 Ogg 页都是音频数据页,里面包含音频包(Audio Data Packet)。这里要特别说明一下音频包的含义。一个音频包并不等同于一个 Opus 编码输出的 Opus 包(Opus Packet)。Opus 编码器最只可以编码单声道或者双声道立体声,所以一个 Opus 包最多包含两个声道的数据。如果要用 Opus 编码多声道环绕立体声,那么只能组合多个单声道或者双声道的 Opus 流来实现。例如一个 5.0 环绕立体声可能由 3 个 Opus 流组合而成:2 个双声道,加上一个单声道 Opus 流。
假设一个多声道音频流由 N 个 Opus 流组成,把 N 个流在同一时间点上的 N 个 Opus 包组合在一起就形成一个音频包。为了在一个音频包里面区分出 N 个 Opus 包,一个音频包里面前 (N-1)个 Opus 包采用带分界(Self-Delimiting)的包格式,最后一个包采用标准 Opus 包格式。另外需要注意的是一个音频包里面的所有 Opus 包代表的时间长度必须相同。
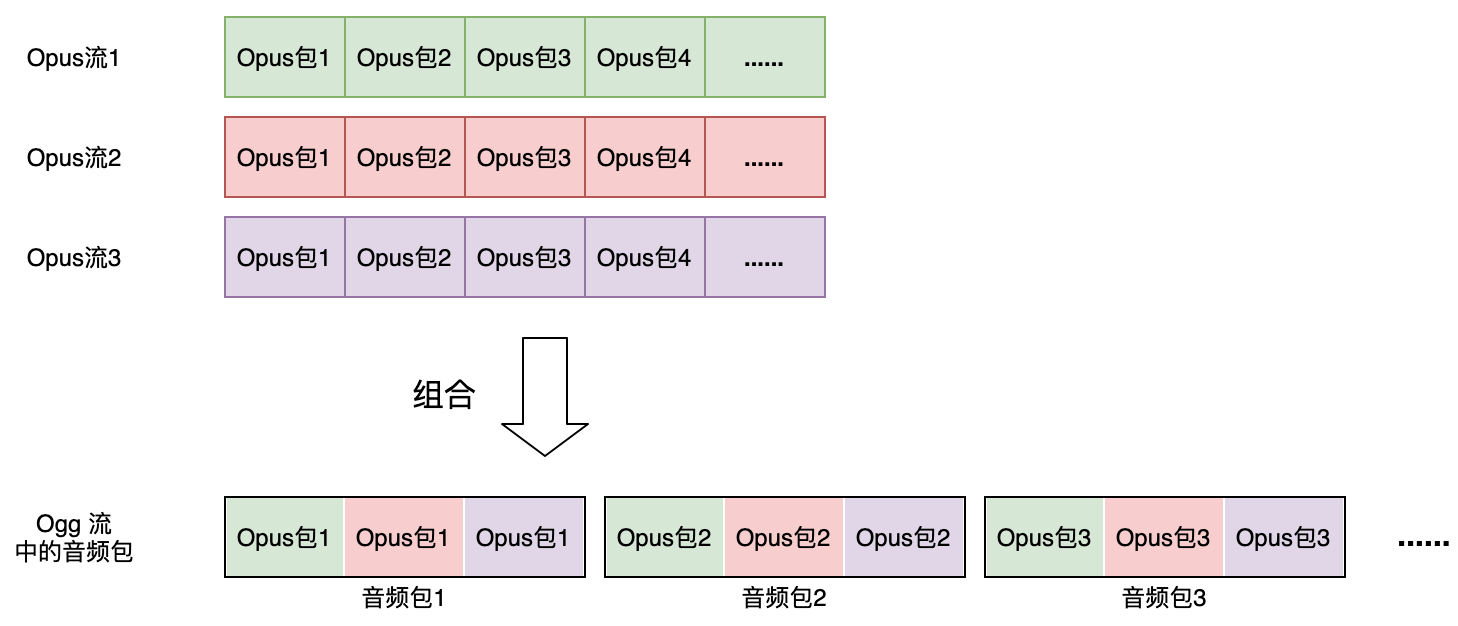
对于单声道或者双声道立体声,N 通常为 1,对于多声道音频来说 N 大于 1。N 的具体值定义在了 ID 头里面,并且在整个 Ogg 逻辑流里面保持不变。
根据声道数,音频一般分为单声道音频(mono)、双声道立体声音频(stereo)、多声道环绕立体声音频(multichannel surround)。
位置数(Granule Position)
根据 Ogg 格式的标准,每个 Ogg 页的头部都有一个位置数字段。位置数至关重要,它代表当前页音频数据的播放时间点。包含 ID 头和包含注解头结尾的两个 Ogg 页的位置数为 0,这是因为这两个包不是音频,因此不占用播放时间。音频 Ogg 页的位置数是从音频流开始到当前页中最后一个完结音频包所包含的总 PCM 采样数。如果一个 Ogg 页里面没有一个完结的包,那么这个页的位置数为 -1(以补码的形式编码)。关于 Ogg 页位置数字段的详细解释,请参考《Ogg 容器格式》这篇文章。
音频 Ogg 页的位置数记录的是按照 48kHz 的采样率解码得到的 PCM 采样数。(并且是按照一个声道的采样数来计算。同样时间长度的音频,多声道的位置数并不比单声道的大)。解码器也可以按照其它采样率来解码,但是因为 Opus 编码时使用的采样率都能被 48kHz 除尽,因此一律按照 48kHz 的解码采样率来计算位置数是一种简单有效的办法。
根据 Opus 标准的规定,一个音频帧最小为 2.5ms,一个 Opus 包最多包含 48 个帧,因此一个 Opus 包的时间长度为 2.5ms 到 120ms 之间,而且长度肯定是 2.5ms 的倍数。 一个帧的时间长度被编码在了 Opus 包开头的 TOC 字节里。解码器解码一帧数据返回的 PCM 采样数一定是和这个时间长度对应的。例如一个 20ms 的帧,按照 48kHz 采样率解码后的采样个数是 960。
根据 Ogg 页上的位置数,解码器可以通过向前或者后项查询,给每个解码得到的 PCM 采样分配一个位置数编号。
流开头可跳过的 PCM 采样数:Pre-Skip
由于 Opus 编码的某些原因,编码器会在音频的开头插入一些无用的 PCM 采样,解码器会解码这些采样,但是解码后会丢弃掉这些 PCM 采样,不播放它们。
Ogg 页的位置数包含了这些插入在前面的 PCM 采样数。要计算实际的 PCM 采样数,应当采取如下公式:
1 | 实际 PCM 采样数 = 位置数 - 前置插入 PCM 采样数 |
播放器上应当显示的播放时间为:
1 | 实际 PCM 采样数 |
在 ID 头里面有一个pre-skip字段,它的值就等于编码器插入的无用 PCM 采样数。
对第一个位置数的限制
对于第一个包含包尾的音频 Ogg 页,其位置数有可能大于实际解码得到的 PCM 采样数。因为有可能是从实时语言流的中间开始接收音频。
尾部可丢弃的采样数
最后一个 Ogg 页,也就是设置了 eos 标志的页,它的位置数可能比实际解码出来的 PCM 采样数小。那么最后多出来的那些 PCM 采样就可以丢弃掉。
ID 头(ID Header)
ID 头(ID Header)包含的数据至关重要,只要理解了里面每个字段的意思,就基本理解了 Ogg 是如何封装 Opus 的。
1 | 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 |
上图是 ID 头的格式。下面详细解释每个字段的意思。
魔数(Magic Signature)
这是 8 个固定的字节,其内容为OpusHead。
版本号(Version)
占 1 个字节,表示版本号,目前版本号的值始终为1。可以把这个版本号看作两部分,高 4 位为主版本号,低 4 位为次版本号。如果主版本号不相同,那么表示两个版本的格式不兼容。
输出声道数(Output Channel Count)
占 1 个字节,表示解码这个音频流需要输出的声道个数,我们把这个声道数记为 C。
前面我们提到过,一个 Ogg 封装的音频流可能包含 N 个 Opus 音频流。这个输出声道数 C 并不等于 N,而是可以取任意值。由于 Opus 的特性,即便是同一个 Opus 流,里面每个包所代表的声道数都可能不一样,每个 Opus 包的声道数都由其开头的 TOC 字节中的 s 标志指定,如下图所示, 0 表示单声道,1 表示双声道立体声。
1 | 0 1 2 3 4 5 6 7 |
编码的时候,编码器会根据输入的 PCM 数据,以及当前编码音频帧的特性,来决定当前编码输出到底是单声道还是双声道。解码的时候,解码一个 Opus 流到底输出一个声道还是两个声道,并不会根据 TOC 中 s 的指示的来输出,实际上因为每个包 s 取值都有可能不同,也不能根据它来解码。而是根据需求,配置解码器,让它解码成单声道或者双声道。当解码配置为单声道,而某个 Opus 包是双声道数据时,解码器会将两个声道的数据求平均合成一个声道的数据。如果解码配置为双声道,而某个 Opus 包是单声道数据时,解码器将单声道数据复制成两个声道的数据。
因为一个 Ogg 流中有 N 个 Opus 流,具体对每个 Opus 流如何解码,是根据声道映射类(Channel Mapping Family)和声道映射表(Channel Mapping Table)共同决定的。这个后面会详细解释。
输入采样率(Input Sample Rate)
占 4 个字节,以小端法表示的无符号整数。代表编码前原始输入的 PCM 采样率。但是并不代表解码后播放语言的采样率。
对于 Opus 这种有损编码来说,编码的时候并不会保留原始的采样率,在编码的时候会根据每个帧的特征决定采用哪种采样率编码。因此同一个流中每个 Opus 包应用采样率可能都不一样,每个包的采样率和对应的带宽由 TOC 字节中的 config 定义。在解码播放的时候,根据下面的实际情况,按照某种采样率解码:
- 如果硬件支持 48 kHz,那么按照 48 kHz 解码。
- 如果硬件最高支持的采样率是某个 Opus 支持的采样率(8 kHz,12 kHz,16 kHz,24 kHz,48 kHz),那么按照这个支持的采样率解码。
- 如果硬件最高支持的采样率小于 48 kHz,那么选择一个刚好大于硬件采样率的 Opus 支持的采样率解码,解码后重采样成硬件需要的采样率。
- 其它情况使用 48 kHz 解码,然后重采样。
当需要将 Ogg Opus 解码输出成 PCM 文件时,输出的 PCM 文件可以按照这个输入采样率来存储。这样解码输出文件保持和原始输入 PCM 一样的采样率,可以让用户不至于困惑。
由于输入采样率对解码并没有多大意义,因此它的值也可以设置为 0,表示未定义。
输出增益(Output Gain)
占 2 个字节,以小端法表示的有符号数。代表解码时,应用到每个采样的增益,单位为 dB。这个数采用 Q7.8 格式表示,16 位中有 8 位代表小数部分,是个有符号的浮点数。假如增益倍数为
假如输出增益的值为 a,解码得到某个 PCM 采样的值为 y,那么应用这个增益得到的值 p 可用如下公式计算得到:
播放器应用这个增益之后会改变声音的音量。
声道映射类(Channel Mapping Family)
占 1 个字节,无符号整数。定义了声道映射的类别。目前只能取值为 0、1、255。根据取值 x,我们把它称为第 x 类声道映射。其具体意思在后面解释。
声道映射表(Channel Mapping Table)
占多个字节。当声道映射类不为 0 时,ID 头里面才包含这个声道映射表。其具体意思在下一节解释。
声道映射(Channel Mapping)
前面我们提到了,一个 Ogg 流里面封装了 N 个 Opus 流。通过声道映射表的定义,这 N 个 Opus 流可以解码出 M + N 个声道。最后根据之前输出声道数的定义可以输出 C 个声道。
除了第 0 类声道映射,在 ID 头里面都编码了如下的声道映射表:
1 | 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 |
第一个字节是 Opus 流个数 “N”(Stream Count),为无符号整数,表示这个 Ogg 流中封装了 N 个 Opus 流。也意味着一个音频包中包含了 N 个 Opus 包。N 不能为 0。
第二个字节是双声道 Opus 流个数 “M”(Coupled Stream Count),为无符号整数。这个数 M 必须小于等于 N,它告诉解码器每个音频包中前 M 个 Opus 包按照双声道来解码,剩下的 N - M 个 Opus 包按照单声道解码。因此解码出来的总声道数为 M + N,总声道数不能大于 255。
声道映射关系(Channel Mapping)占 C 个字节。每个字节对应一个输出声道,它的值表示解码出来声道与输出声道的对应关系。这个表就相当于建立了 M + N 个解码声道与 C 个输出声道的关系。假设某个字节的值为index,这个值要么是小于 M + N 的,要么等于特殊值 255。假如index小于 2*M,那么解码出的第index/2个 Opus 流是个双声道流,如果index是偶数,输出声道就取这个流的左声道,如果是奇数,就取右声道。假如index大于 2*M 且小于 255,那么解码出的第index - M个 Opus 流是单声道的,那么输出声道就取自这个流。如果index等于 255,那么输出声道就是纯粹的静音。
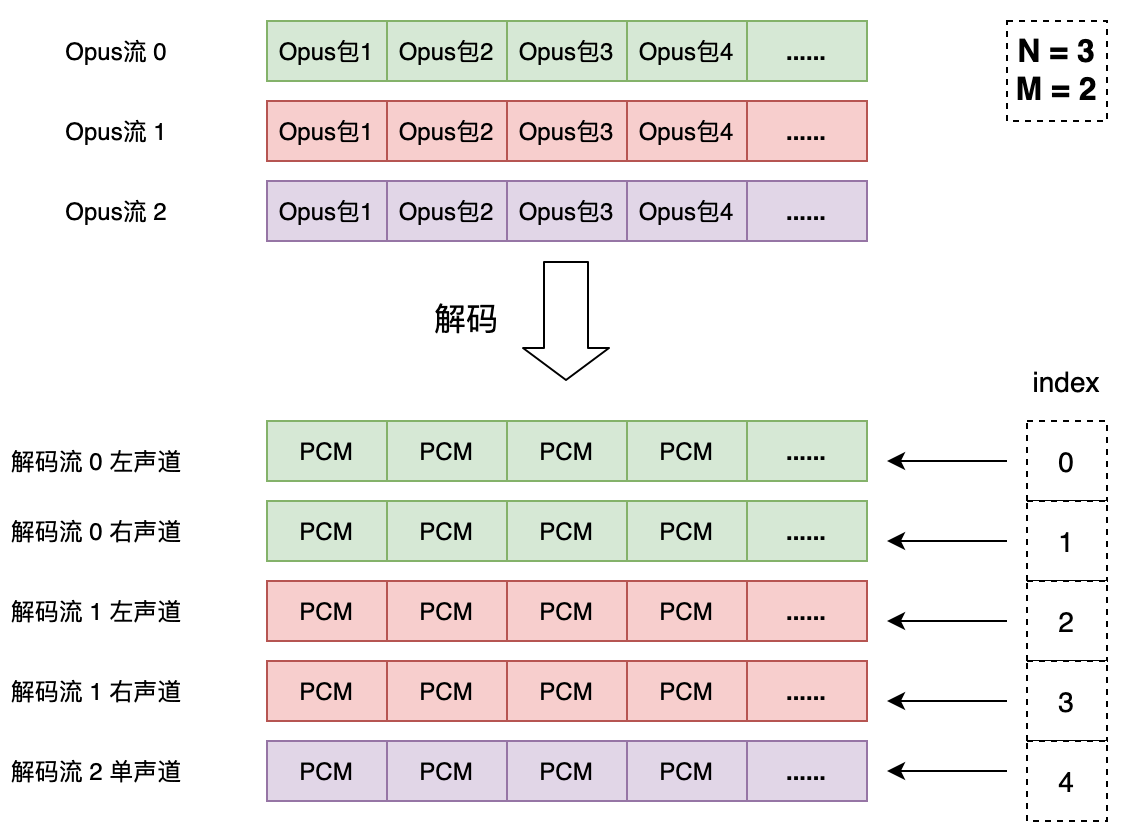
输出声道数 C 并不一定要等于解码声道数 M + N。相同的index值可能会多次出现,也就是说多个输出声道对应相同的解码声道,同时有些解码声道没有对应的输出声道。
每个声道映射类所允许的声道个数和含义都不一样,下面详细介绍各个声道映射类对应的声道含义。
第 0 类声道映射
允许的声道个数:1 或者 2。表示单声道或者双声道音频。
对于第 0 类声道映射来说,ID 头里面不包含声道映射字段。它的 N 默认等于 1,表示 Ogg 流里面只封装了一个 Opus 流。C 等于 1 或者 2,表示输出单声道或者双声道,M 等于 C - 1。因此可以看出,输出声道就对应这个 Opus 流按照单声道或者双声道解码出来的 1 个声道或者 2 个声道。
第 1 类声道映射
允许的声道个数为:1 到 8。每个声道对应不同的扬声器排列方式,其输出声道排列如下:
- 1 个声道:单声道。
- 2 个声道:双声道立体声。声道排列:左声道,右声道。
- 3 个声道:线性环绕立体声。声道排列:左声道,中声道,右声道。
- 4 个声道:四声道环绕立体声。声道排列:左前声道,右前声道,左后声道,右后声道。
- 5 个声道:5.0 环绕立体声。声道排列:左前声道,中前声道,右前声道,左后声道,右后声道。
- 6 个声道:5.1 环绕立体声。声道排列:左前声道,中前声道,右前声道,左后声道,右后声道,低音效(LFE)声道。
- 7 个声道:6.1 环绕立体声。声道排列:左前声道,中前声道,右前声道,左侧声道,右侧声道,中后声道,低音效(LFE)声道。
- 8 个声道:7.1 环绕立体声。声道排列:左前声道,中前声道,右前声道,左侧声道,右侧声道,左后声道,右后声道,低音效(LFE)声道。
这些声道的排列和含义和 Vorbis 格式是一样的,但是和 WAV 和 FLAC 格式不一样。如果需要在这些格式之间做转换,那么需要注意重新排列声道顺序。
第 255 类声道映射
允许的声道个数为:1 到 255。但是每个声道没有特别的含义。播放器一般不会播放这一类音频流。某些软件的实现可以将每个声道存储成单独的 PCM 文件,但是对于index值为 255 的声道是不输出任何文件的,因为这代表着静音。
未定义的声道映射类
声道映射类 2 到 254 是保留的类,目前没有任何特殊含义。
注解头(Comment Header)
注解头的结构比较简单,如下图所示:
1 | 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 |
注解头也是以 8 个字节的固定魔数(Magic Signature)开头,其值固定为OpusTags。
厂商字符串长度(Vendor String Length)占 4 个字节,是小端法表示的无符号整数。它代表后面厂商字符串(Vendor String)的长度,厂商字符串不包含 null 结尾的字节。厂商字符串用于存储编解码器和封装容器的名字等相关信息。
注解列表长度(User Comment List Length)占 4 个字节,是小端法表示的无符号整数。它表示后面注解的个数。其中每个注解由两部分组成,一个是注解字符串长度(User Comment String Length),另一个是注解字符串(User Comment String)。
注解字符串使用NAME=value的格式,注解标签名与 Vorbis 格式中定义的一样,包含了:ARTIST、TITLE、DATE、ALBUM,等等。
参考文献:
[1] Self-Delimiting Framing: https://tools.ietf.org/html/rfc6716#appendix-B
[2] Ogg Vorbis I format specification: comment field and header specification: https://www.xiph.org/vorbis/doc/v-comment.html
[3] Ogg Encapsulation for the Opus Audio Codec: https://tools.ietf.org/html/rfc7845
[4] Ogg容器格式: https://chenliang.org/2020/03/14/ogg-container-format
[5] Opus 音频编码格式: https://chenliang.org/2020/03/15/opus-format/